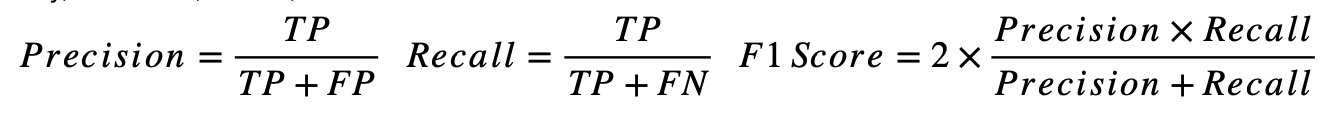
I began researching this early last year with the idea of building some kind of service that automagically exploit computer systems. That is, autonomous hacking powered by AI that can plan and iterate based off of new information, i.e. reasoning and execution. Then Anthropic released a report showing that the Chinese had adapted methods that research papers pioneered, and then I started seeing job specs for ‘AI pentesting engineer’ and all these startups promising agentic red teaming. I knew then that I was already behind the curve, so it was best to move on to something more promising (and more interesting) - AI vulnerability discovery. While researching the latest advancements I came to find that there was a discrepancy between academic research and industry labs (read: defense contractors), in that the academic research seemed hard stuck at static analysis (more on that later) while defense contractors had seemingly overcome this (unconfirmed, but reading between the lines it seems pretty obvious) and were beginning to discover 0days at scale. More recently, I’ve seen various startups and independent researchers lay claim to discovering copious amounts of ‘critical’ 0days in open source libraries. So I’ve missed the boat on this, too. This is why I’ve decided to write an article about my journey and research (for a general readership i.e. technical but not overly autistic).
Almost immediately after the release of ChatGPT in late 2022, security researchers and academics started tinkering with teasing out cyber security capabilities. AI engineers and the companies that employ them had long been influenced by AI safety research, so they were already prepared with various benchmarks to test capabilities. The way this works is they have a data set, in this example it’s often a malicious cyber security question or a CTF-style exercise, and they launch the model against it to see if a) it agrees to perform a malicious cybersecurity task; and more importantly b) if it actually succeeds. It used to be rather trivial to fool an LLM into playing along, and this was done through context engineering - simply tell the model you’re a security researcher and it does whatever you want (if only real life were that straightforward…). Later iterations applied guard rails and various security controls (like safety classifiers, i.e. a ‘safety-aligned’ model that sits in-between input and output and blocks malicious queries) such that it’s now much harder to fool frontier models, but it’s still very much possible, particularly with prompt engineering jailbreak techniques (or even better - abliterating open weight models).
These benchmarks gave researchers a metric by which they could measure the success of various model architectures specifically designed with offensive cybersecurity in mind. The first forays were just simple ‘point-and-click’ attacks i.e. one-shot prompts with a single model. Then came context engineering, few-shot, and chain-of-thought prompting, which translated to better results. Next came various breakthroughs such as retrieval augmented generation (RAG) which gave models a database storage method they could draw from (if context memory is RAM, then RAG is the HD), and fine-tuning bespoke models on pure cybersecurity datasets, which resulted in more powerful and more capable models with domain-specific specialist models outperforming more generalized ones on niche domains.
The real game changers, though, were agent scaffolding, tool usage, and multi-agent architectures, leading to agentic AI and complex orchestration frameworks and architectures. In layman’s terms, this allowed models to use tools (like nmap, curl, a mouse and keyboard, and then later an entire OS like a Kali VM); it allowed models to plan, reason, and execute actions on objectives, independent of human oversight (though often with a human’s instructions and a human-in-the-loop for critical decisions); and it chained models together, often in a hierarchical structure where a frontier model was at the top and acted as the planner/organizer, while other less capable (and less expensive) models would delegate tasks and then domain-specific bespoke models would focus on specific niche tasks or knowledge sets.
Most big AI labs tend to release frequent threat intelligence reports detailing the many creative ways their models are being abused, how the malicious actors were discovered, and what the labs have done to make sure it never happens again. Most of these reports aren’t particularly important, and are typical of how increasing AI capabilities are being weaponized. However, one bombshell report dated Nov. 2025 by Anthropic showed that Chinese state-sponsored threat actors were weaponizing Claude Codes to conduct a sophisticated cyber espionage campaign. The operational architecture closely reflected what academic researchers in 2024 had build and coined HPTSA - hierarchical planning and task-specific agents.
The Chinese differed slightly in that instead of using task-specific agents to target niche domain activities (such as network scanning, windows privilege escalation, etc.), they leveraged Anthropic’s native (and open-source) Model Context Protocol to call tools. Same method, different implementations. The age of autonomous offensive AI is (almost) upon us. To quote from the Anthropic report: “AI executed approximately 80 to 90 percent of all tactical work independently, with humans serving in strategic supervisory roles.”
Now vulnerability discovery is a fair bit harder than pentesting. It’s not just because of significantly more prerequisite hard skills, but because it requires a creative spark in that it’s not simply pattern matching - it involves a bit of guesswork, or rather intuition, built up through experience. Further to that, a lot of it is feeling around in the dark until you stumble on something useful, thus the gut feeling of veteran security researchers is just as important as the dogged analysis itself.
The traditional vulnerability discovery process typically begins with target selection and deep research, followed by a combination of static and dynamic analysis, automated testing techniques such as fuzzing or automated exploit generation (AEG). The end goal is to identify primitives (initial footholds such as arbitrary read/write functionality) and transform identified vulnerabilities into functional exploits capable of achieving high-impact objectives such as arbitrary code execution.
0-day discovery distinguishes itself in that it presupposes the complete absence of any prior knowledge of the vulnerability, meaning existing exploit primitives, known patterns, or reference security patch notes offer no reliable launch pads. Consequently, the discovery process takes much longer, operates under significantly greater rates of uncertainty and results in higher false positives. In practice, exploit patterns tend to repeat themselves across code bases and vulnerability categories are well-known and well-understood, theroetically lending itself well to function approximation by AI systems.
With LLMs being the greatest function approximators in the known world (perhaps with the exception of us humans), these patterns can be functionally approximated and reproduced across novel targets. Efforts to incorporate AI into the vulnerability discovery process have borne fruit, with even simple solutions using zero-shot prompting and “no scaffolding, no agentic frameworks, no tool use”, having already discovered new and complex 0days in the Linux kernel. More complex architectures such as the OpenHands scaffolding have discovered dozens of 0days across hundreds of software projects, even with zero-shot prompting. This already proves that frontier models have already grown powerful enough to autonomously discover computer vulnerabilities, including 0days, at scale - yes, while an expert human cannot easily be replicated (cloning is not yet feasible and upskilling/retraining can take months or even years), an LLM or some architecture can be easily cloned in the cloud with a simple YAML file.
It’s obvious then that the future of useful and effective AI is building sophisticated architectures with multiple models hierarchically interacting. Thankfully, the literature has a single word for this: orchestration. AI orchestration techniques promise further advancements in AI-assisted vulnerability discovery, and can be broadly categorized into five distinct methods:
The most gold standard for judging the effectiveness of AI-assisted vulnerability detection is the F1 Score. This is the harmonic mean of Precision - in the set of all identified vulnerabilities, how many were actually true positives - and Recall - in the set of all real vulnerabilities, how many were identified. The F1 Score combines these measures into a harmonic mean, punishing big differences between precision and recall. This is important in binary classification tasks like vulnerability detection (a data set either has a vulnerability present or does not), where class imbalance is present (it is much rarer to find a data set with a vulnerability present).
Formally, they can be defined as:
A higher F1 Score = a better overall performance in vulnerability classification. In other words, fewer missed vulnerabilities and of those that are discovered, a lower rate of false positives. This essentially translates to more efficient vulnerability detection. Ceteris Paribus, the higher the F1 Score, the greater the chance a vulnerability, if it exists, is discovered.
One would think that the larger the model (the more parameters), the ‘smarter’ it is and thus the higher the F1 Score would be. This is not always the case - while data suggests a correlation between model size and F1 Score, there are plenty of outliers. Specialist models trained on coding data sets actually perform worse than general purpose models for vulnerability detection. Some smaller models fine-trained on vulnerability datasets (i.e. CWE) with general frontier models as ‘teachers’ seemingly far outperform much larger models with respect to overall F1 Score.
Sadly, this is the extent of what academics have come up so far - fine-tuning existing LLMs on vulnerability datasets; agent scaffolding; and simple static analysis. However, DARPA hosted the AI Cyber Challenge (AIxCC), offering millions of dollars in prizes to top competitors. The collaborators read like a whose who of big tech/AI companies and well-known cyber security organizations. While the premise of the challenge was to ‘patch’ vulnerabilities, the true objective is quite obvious - AI-assisted 0day discovery. This was facilitated by creating ‘synthetic’ vulnerabilities in various systems, with the winners discovering 86% of these synthetic vulnerabilities. DARPA calls these offensive AI ‘Cyber Reasoning Systems’, a fitting name for an autonomous vulnerability discovery system.
Incumbents will claim that AI-assisted vulnerability discovery is an exciting new development in the field of cyber security precisely because it empowers defenders to find and fix critical vulnerabilities before they can be exploited by threat actors. This is a convenient half-truth. While there are initiatives that certainly support this fiction, e.g. Google’s Bigsleep and Project Zero, most of these efforts will be put towards finding and stockpiling 0days for nation states, as it is only those nation states that can a) hire and/or coerce talented engineers into building complex AI system architectures; b) access base (read: pre-defensive-alignment-tuned) models from top AI labs, obviating the need for jailbreaking; and c) have the resources necessary to massively scale and parallelize workflows. Contrast this with the creators and maintainers of the software that we use on a daily basis, often either large companies for whom cybersecurity is a cost centre, a money sink, a black hole that produces no tangible profit; or small teams of independent passionate researchers maintaining open-source software who don’t always have the necessary resource to do good security. The good news is that there are software products being built right now whose stated aim is to provide a kind of AI-powered vulnerability discoverer for engineering teams to use against their code before it goes live, with the intention of finding and fixing any security vulnerabilities. One example being OpenAI’s Aardvark. The bad news is that these products will pale in comparison to what nation states will be have at their disposal.
There are at present a number of limitations to AI-assisted vulnerability discovery. Namely, researchers are soft-locked at the ‘static analysis’ stage of the discovery process. While AI has made remarkable progress in vulnerability discovery by scanning static code repos in open-source projects, this success has not (yet) been replicated in dynamic analysis. Were AI able to make full use of security tooling, both command-line and GUI, and further able to iterate and reason and even, dare I say (write) it, show some nascent creativity, then we would be absolutely cooked.
With regard to pentesting, agentic AI has already made this possible, albeit often with a human-in-the-loop. This isn’t exactly a surprise - ethical hacking (and unethical hacking) has long been pushing for more automation, more parallelization, more scaling. From one-click exploit engines like Metasploit and massive IoT botnets like Mirai, this has been going on for years and years. Now that we have frontier models capable of reasoning, planning, and orchestrating, it’s only natural that this should extend to pentesting. In fact, it’s become quite the popular PhD topic, and many companies, from incumbents through to startups, are building out offerings that do exactly that - automate the entire pentesting process from start to finish. What should worry us is the accessibility of it all - even a layman with little security knowledge can prompt a misaligned model to conduct a malicious cyber campaign. There are AI-specific honeypots out there, on the internet, and they have footprinted AI attacks with very high confidence, starting a few years ago and ramping up every year…
We live in interesting times. A pessimist would preach Ragnarok, but methinks that while yes of course this will create a much more dangerous security environment, it will likwise go a long way towards finally cracking the whip of defensive controls and forcing software vendors to step up and secure their products or get exploited into oblivion, something akin to Schumpeter’s creative destruction, but for cyber security - call it cyber destruction, or the age of actually secure software (until an APT chains five 0days and obliterates all the security).